





















.svg)











.svg)




















.png)


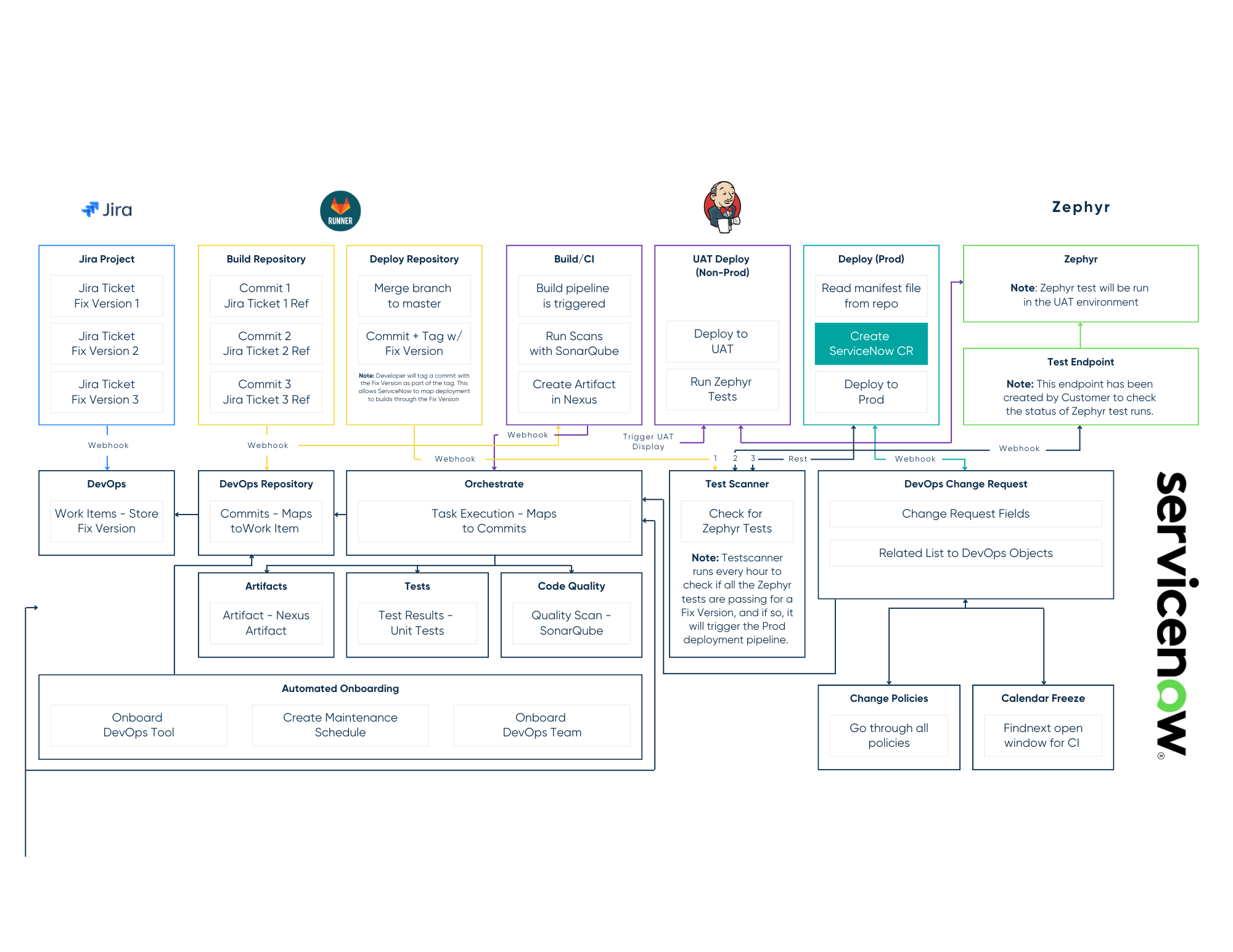
The ServiceNow Configuration Management Database (CMDB) is designed to provide an accurate, comprehensive map of an organization’s Configuration Items and their technical relationships to support observability, operations, and strategic alignment of IT infrastructure. But duplicate Configuration Items (CIs) undermine that foundation, leading to unreliable relationships, skewed reporting, and broken downstream processes like Change, Incident, and Service Mapping. In this blog post, we’ll see how targeted fix scripts can be leveraged to safely and efficiently merge duplicate records at scale.
The Root of the Problem
Duplicates commonly arise when multiple data sources—such as Discovery, SCCM, cloud integrations, and manual imports—populate the same CI classes without consistent identification rules. ServiceNow’s Identification and Reconciliation Engine (IRE) is designed to prevent this, but it must be properly configured with well-defined identifiers, precedence rules, and source priorities to function as intended, and historical data collected before these configurations have been made may still require attention. Take database instances, for example. An organization may have imported database instances into its CMDB in bulk before effectively implementing Discovery to provide the same information, and differences in naming conventions and other attributes may have resulted in Discovery making entirely new records instead of updating the existing ones. In this scenario, a company would want to prioritize its Discovery records because of their near real-time insights into the configurations, but also would not want to lose all the relationships to ITSM records, historical data connected to its child databases, or manual attributes populated in its existing database instance records. How could a company go about meeting both of these goals?
Finding the Pattern
When a customer is dealing with thousands of such records, manual remediation is no longer viable, and a targeted fix script is necessary. The first step is to identify a way of systematically identifying duplicates. Your team has already determined that there are duplicates, but how do they know they exist? For the case of database instances, it may be because the server name and instance name are the same, but were not automatically treated as the same record because of how Discovery formatted the name compared to how it was historically formatted. E.g., it may be a difference between [instance name]@[server name] vs. [server name]\[instance name]. As long as there is a consistent pattern or patterns like this, you can systematically identify the duplicates by parsing the attributes to match a normalized value, either by updating the names of the old records directly or caching an array of your database instance records with the normalized name as a new array value (e.g., in this case parsing out “@” and “\” and caching a value of [server name] - [instance name]). Such a cached array of normalized values would allow you to efficiently identify duplicates after standardizing the names without having to make additional calls to the server.
After identifying the duplicates, it’s time to remediate. The same array that identified them can be leveraged for this task if the Sys IDs of the candidate records were included in the array, as well as the Discovery Source field and any other attributes you need to use to identify which records to keep and consolidate. We then have to identify three things:
- What attributes need to be copied over?
- What types of records within
cmdb_rel_cineed to be pointed to the kept record? Do these need to be deduplicated? - What other places in ServiceNow reference your records?
Depending on the answers to these questions will determine the complexity of the task. Perhaps there are only a few attributes you care about preserving, or perhaps you want to update every empty field on the kept record with non-empty fields on the old record (in which case, a function to loop through all the dictionary values of the record may be needed). If the child database records may also be duplicated, you will have to search for each of them in cmdb_rel_ci and consider the attributes and rules of selection for them as well. If that criteria is significantly different, it could increase the script’s complexity and require extra care and attention. The same is true for considerations of cross-platform references to the CI. Some references may be more important to preserve than others for your use case, but at a minimum you will likely want to repoint references on the task table and the Affected CI table, both for the database instance as well as for any child databases that may also require deduplication.
Delete Last, Validate First
Deletion of duplicate CIs should be the very last step, and only after you have confirmed that the script has done everything else correctly. You may even wish to export the list of Sys IDs identified to delete and use them as an input for a second fix script after validating that all the attributes and relationships have been copied over to the kept records.
Fix scripts must be treated with caution. They should be thoroughly tested in non-production environments, executed in controlled batches, and paired with clear rollback strategies. Poorly designed scripts can break CI relationships or corrupt critical service maps just as easily as they can clean them up.
The Long-Term Answer
The long-term solution is governance. Continuous monitoring, ongoing refinement of IRE rules, disciplined source onboarding, and periodic validation ensure duplicates don’t reappear. When prevention and remediation work together, the CMDB evolves into a trustworthy system of record—one capable of supporting automation, analytics, and informed decision-making at scale. Whether you're dealing with legacy data issues or scaling Discovery and integrations, CMDB health requires both strategy and execution. Connect with RapDev to build a CMDB you can actually trust.
