





















.svg)











.svg)













.svg)


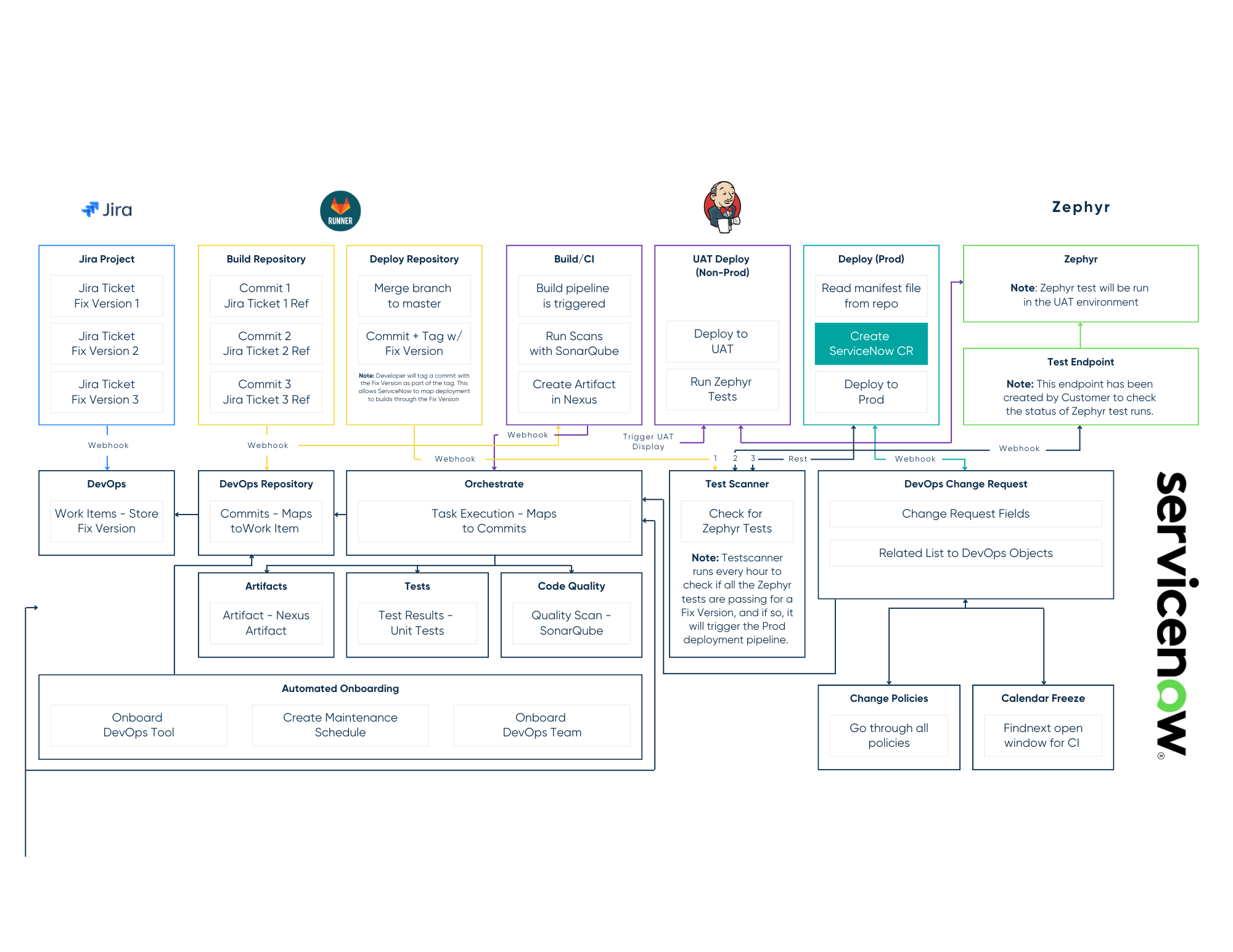
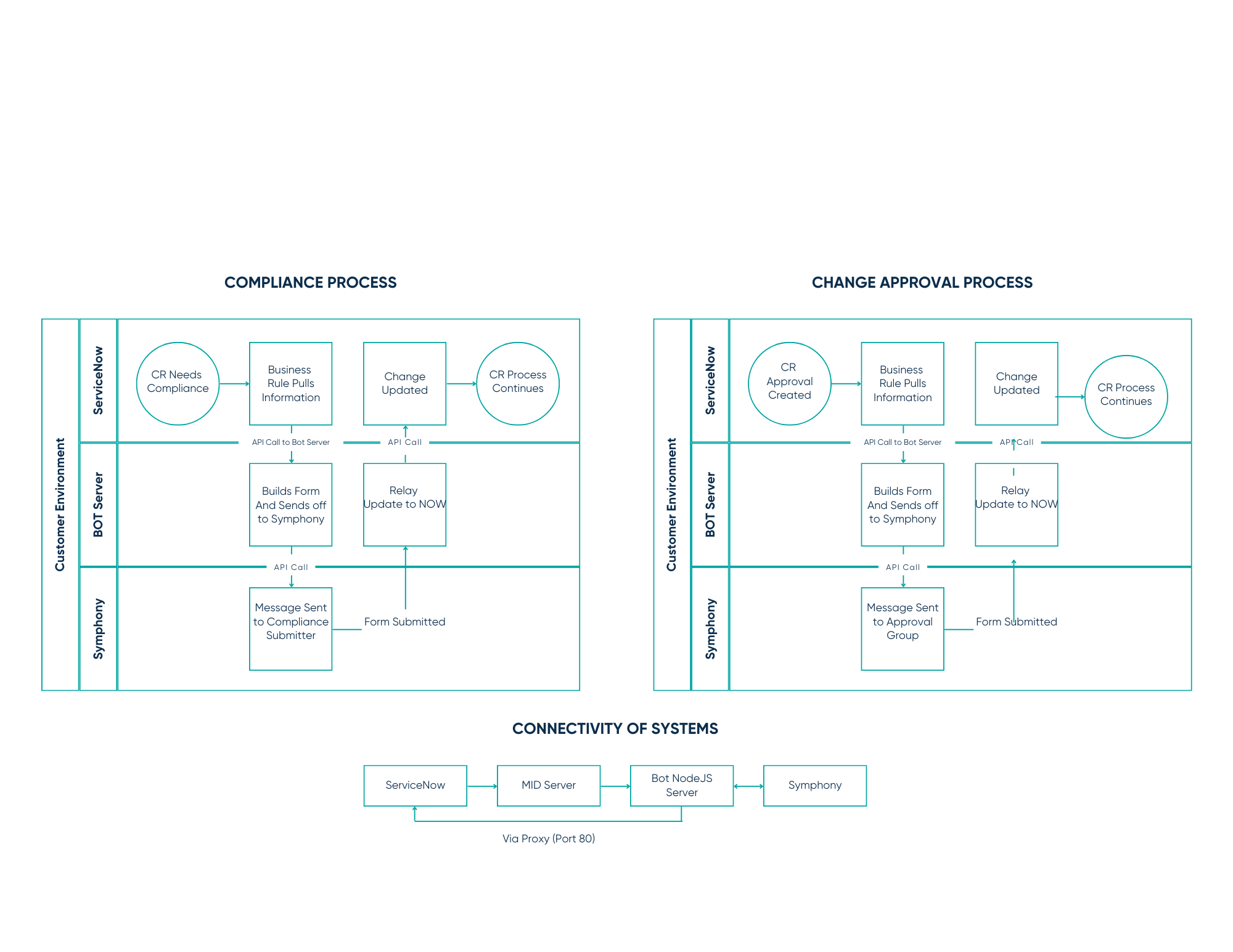





.png)


A DevOps culture needs failure. There, we said it! But know this: it should be countered by learning quickly, adapting, and implementing these learnings to future-proof your systems. The point here is for your teams to experiment in a structured environment, where speed of failure allows for speed of discovery – specifically, discovering ways to improve your systems and products.
Most managers won’t be completely open to welcoming a fail-fast culture, but if you’ve beaten around the Agile bush long enough, you’ll know it’s essential for fine-tuning processes and spotting security flaws before production. A lot of software engineers expect some legroom to experiment freely when building successful products – why shouldn’t the entire Engineering department be afforded the same safety barriers? Many teams will embrace a “DevOps culture” but not see any improvements to their deploy velocity, this is almost always due to avoiding failure.
Making small changes regularly, and using the right tools to facilitate these changes, will be crucial when introducing a healthy amount of fail-fast culture, especially when ensuring the interoperability of your developers and operations folk. You’ll also want to know when to back out of decisions and changes, rather than avoiding the call altogether – this habit will serve you well when things go sideways.
Failing safely will be a challenge, but something that can be coordinated, practiced, and prepared for. Let’s take a closer look at what this can mean for your team, and when your decision-making skills will be put to the test.
The Good, The Bad, and The Ugly of Failure
Think back to a time when there’s been an issue in production, or when a big stack of customer data suddenly became unavailable. Something’s gone wrong, and you need to fix it now. One barrier to reaching a solution could mean that someone needs to “own” the fault, to appease the manager overlords. I won’t be the first to tell you that this isn’t going to solve anything for anyone.
Fail-fast culture relies on learning and adapting… and you guessed it, fast. You want to make some mistakes in order to prevent them in the future, and this is especially true of your general architecture. Does that mean going ahead and burning down the whole building? Definitely not, but you’ll have to feel the heat now and then if you want your systems to withstand the fire.
No one wants to be blamed for failures or mistakes – especially if the cost is high. Blaming and shaming isn’t going to create a culture that fosters innovation and calculated risk. To accept a “fail fast, fail often” mindset, incremental change and rapid feedback loops are as essential as the terminal. A mantra that has always worked for me is “a failure is an indication of a system deficiency, use it as an opportunity to improve your overall system posture”
Incremental Change to Successfully Fail Fast
To get to this zen-like state, you’ll want to invest heavily in CI/CD, with a bunch of automation of code batch building, testing from the outset, and pushing to production with oversight. The rewards of this approach speak for themselves: fewer bugs, better cost-efficiency for your organization, and a healthier environment for experimentation, enabling you to fail fast.
I’ll let you in on another tactic that’ll galvanise your DevOps work. Get your team, and yourself, used to failing fast by bringing in planned, intentional failures that can be executed in a controlled environment. Planned failures?! Exactly this.

Call them what you will: dress rehearsals, dry runs, whatever works – a coordinated event where your team plans to deal with a specific technical mishap to be better prepared for when your stack is really at risk. Maybe it’s latency related? Or navigating a code change gone awry? You’ll want to narrow down the few blind spots you have and get working on practicing their resolution. This topic deserves a post entirely of its own, but trust me for now, it’ll do wonders for your team in terms of accepting and learning from failures quickly and blamelessly.
Making the Call and Making the Switch
Decision-making in challenging times will be another crucial asset in your overall mindset shift. Being the person who makes the call to cut off failing services or resuscitate others will free up the rest of your team to think of the solutions needed in a crisis. Being able to rely on back-up tech helps you tremendously in this regard. Think cloud for the failover of on-prem services, or the databases you’ve intentionally buffed up for heavy load – having a Plan B for your critical infrastructure is a must.
By failing frequently, it no longer becomes critical; it’s controllable, easy to overcome, and most importantly, easy to fix. Incorporating feedback is vital to identify what needs repair – that feedback will come from precisely how you and your team react to these challenges.
There will always be kinks to iron out when adopting a fail-fast culture, but as long as everyone is willing to go the distance, have shared goals, and feel psychologically safe to experiment in a blame-free environment, the transformation will be monumental for all involved. Agile meets DevOps, eat your heart out.
In future posts we’ll dive a little deeper into different tactical ways to fail fast, including deployment mechanisms, failover methods, etc

.svg)