





















.svg)










.svg)












.png)





.png)



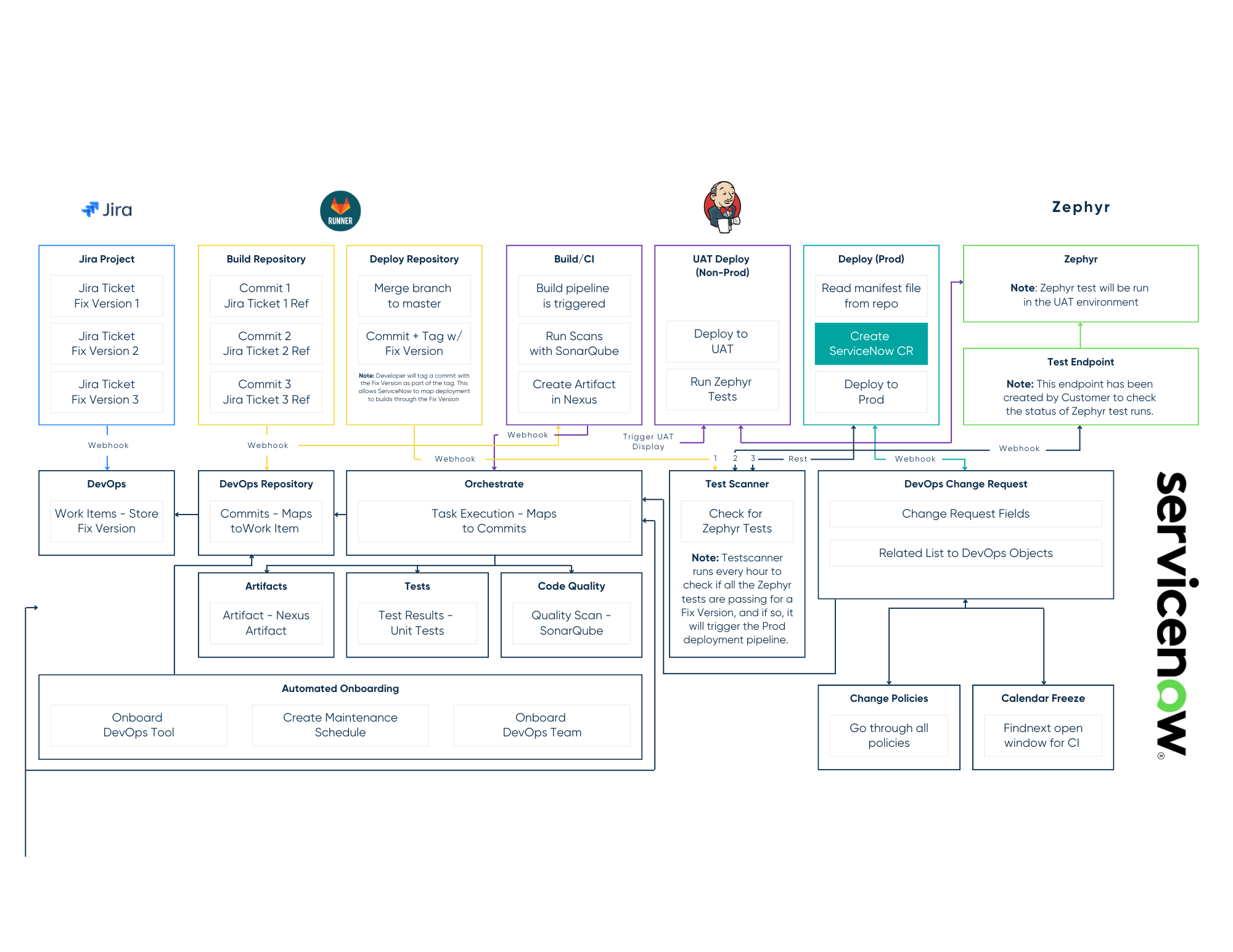
Most benchmarks for coding agents don't fail because the agents are bad. They fail because the task — "fix this bug in this open-source repo" — only covers a thin slice of what people actually pay agents to do at work. The bigger, messier, less-photogenic slice is managing a closed-source SaaS platform: keeping its configuration sane, its integrations healthy, its governance intact, and its upgrades survivable. There is no repo to fork. There are no unit tests to run. And yet this is the work that platform owners, in-house admin teams, partners, and managed-service providers spend most of their week on.
We built asm-bench because we wanted to know — honestly, and without grading on a curve — how good current agents actually are at that work. And we wanted everyone else to be able to know it too.
Asm-bench is open source under Apache 2.0, lives on HuggingFace, and starts with ServiceNow. Datadog and more platforms are next.
Why the Existing Benchmarks Don't Cover This
If you've followed agent evaluation for the last couple of years, you've seen a healthy explosion of code-centric benchmarks — SWE-bench, FeatureBench, the various agentic-coding leaderboards. They've done real work, and the field is better for them.
But the moment an agent's job description shifts from "modify this source file" to "manage this platform," the assumptions break:
- No source repo. You can't
gitcloneServiceNow. You evaluate against the platform's real semantics — encoded queries, ACLs, business rules, catalog workflows, ATF, upgrade-skip remediation, integration design — not against a test runner. - State, not files. A good outcome is "the CMDB no longer has duplicate CIs and the relationships are still intact," not "the diff applies cleanly."
- Governance is the work. Change control, blast-radius limits, scope contracts, refusal-when-asked — these aren't side quests. A naive agent that just does whatever the user asks has already failed a significant fraction of the real workload.
- Closed-book operators. The people doing this job in production cannot share their tickets, their sys_ids, or their integration designs. Any benchmark built from scraped customer artifacts is either contaminated or leaked, or both.
So evaluating an agent on this work needs a different type of benchmark. That's what asm-bench is.
What's in the Box
Each task in asm-bench is one self-contained JSON record validated against a schema. It carries:
- A system prompt and user prompt that frame the job
- An initial state of the platform (the fixtures the emulator boots with)
- The allowed tools the agent is permitted to call
- A list of verifiers that decide whether the work was actually done,
- Governance metadata — blast-radius cap, scope contract, refusal category
- A do-not-train canary GUID embedded in every task file
Tasks are organized by platform and by domain. The first release ships about a hundred ServiceNow tasks across at least 25 domains including: ITSM, catalog, upgrades, platform health, integrations, custom integrations, governance, GRC, TPRM, ITAM, SecOps, Now Assist, SPM, DevOps, Discovery, CMDB hygiene, event management, service mapping, Service Graph Connector, environment management, cross-env promotion, break/fix, negative refusals, AIOps roadmap, and instrumentation probes.
The evaluation runs through a platform emulator — an LLM role-playing the platform's responses against a documented persona — so you don't need a prod sandbox per customer to grade an agent. The emulator contract is described in benchmark docs.
Verifiers, Not Vibes
The single design decision that matters most in a benchmark is "how do you know the agent did the job?" asm-bench answers it with a layered verifier model:
- Deterministic verifiers first.
state_assertion,transcript_assertion, andoutput_formatchecks run before anything else. They decide theresolvedflag. If the post-task state isn't what it needs to be, the task is unresolved — full stop, no rubric can rescue it. - LLM rubrics second, weighted. Soft qualities (clarity of the change, quality of the rationale, fidelity to the scope contract) are scored by an LLM judge. Rubric weights in a task must sum to 1.0; a weighted score below the threshold flips
resolvedback to false. - Two-judge agreement. Rubric grades are run by two judges independently, and we target Cohen's κ ≥ 0.8 across the corpus. Disagreements get flagged rather than averaged away.
The point of this layering is that you can't pass an asm-bench task just by sounding like you did the job. The platform state has to actually reflect the work.
Contamination Resistance Is a First-Class Feature
If a benchmark's test split ends up in a model's training corpus, the benchmark is dead — quietly, and usually before anyone notices. asm-bench is built on the assumption that this will be attempted, and attempts to make it expensive.
- Three-way split, asymmetric publication. Train and Dev are public on HuggingFace. Test is never published — only its task IDs and SHA-256 hashes. Submissions go through a leaderboard API, not a local file.
- Canary GUID in every task file. A grep check in CI fails the build if a task file is missing the canary. The canary lets honest model developers detect contamination in their own corpora and lets us detect it in deployed models. See CANARY.md.
- Versioned, deprecated, not deleted. Tasks have
created_atand version tags; old leaderboard rows pin to released tags so a "fix" to a task doesn't silently rewrite history. - Synthesized, not scraped. Every task is synthesized from anonymized aggregate platform-operations patterns. No customer names, no real sys_ids, no verbatim ticket text. The full provenance rules live in the datasheet.
None of this makes contamination impossible. It makes it visible, attributable, and auditable — which is the realistic bar.
Reporting Like Grown-Ups
A single leaderboard number is not enough to make a buying decision, and probably not enough to make a research decision either. asm-bench reports a vector of metrics, in the HELM tradition:
resolved— did the agent actually complete the task?governance_compliance— did it stay inside the scope contract?scope_violation— did it touch things it wasn't supposed to?blast_radius— how much state did it change?hallucination— did it invent tools, fields, or facts?latencyandcost— what did this performance actually cost?
We also report pass^k with Wilson 95% confidence intervals (in the τ-bench tradition): k ≥ 3 trials per task, per-domain CIs, and a refusal to make rank claims unless CIs are disjoint. If two agents are statistically tied, we say they are tied.
The judge model is pinned (ASM_JUDGE_MODEL, default claude-sonnet-4-6) and submitters cannot override it from the leaderboard. The grading rubric is part of the public task definition.
Why This Should Matter to Two Very Different Audiences
For people building agents: asm-bench gives you a target that rewards the things that are actually hard about enterprise platform work. If your agent gets better at scope contracts and governance refusals, the score goes up. If it gets better at deterministic state outcomes, the score goes up. If it gets better at speed-running tasks by guessing, the score does not go up, because the verifiers don't let it. That's the kind of gradient we want the field to climb.
For people buying agents: asm-bench gives you a way to ask "does this thing actually do my job?" without taking the vendor's word for it. The metrics are multi-dimensional on purpose. An agent with a higher resolved score but a worse scope_violation score is not strictly better — it might be strictly worse, depending on what you're buying it for. The pass^k confidence intervals let you tell the difference between "this is a real capability" and "this happened to work once in the demo." That's the kind of evidence procurement teams should be able to get before they sign anything.
We think both of those audiences benefit from the same thing: an objective measurement that doesn't depend on the goodwill of the people building the agents or the people selling them.
Try It
Everything you need is in the repo:
make run-test will refuse, and that's the point. Submissions to the test split go through the leaderboard.
runner/run_one is a working OpenAI-shape agent driver: it speaks /chat/completions with messages and tools, dispatches tool calls to the emulator, and loops until a final message or the turn budget runs out. To submit, stand up an endpoint that speaks that shape (or set ASM_AGENT_PROTOCOL=anthropic to swap shapes), point the runner at it with --agent-endpoint, and run the dev split. The operator's guide is in docs/harness.md; the methodology — splits, contamination model, verifier model — is in docs/methodology.md; the scoring details are in docs/scoring.md.
Taking the Benchmark for Real
Train and dev are public so you can iterate honestly against the same emulator and verifiers we use. The test split is held privately — only task IDs and content hashes are published — so a leaderboard row stays meaningful release-over-release. Landing a row goes through us:
- Wire your agent up against the dev split locally until you're happy with how it runs. The runner produces a signed envelope (
makegen-signing-key, thenrunner/runner.py --emit-envelope --signing-key …) that's the wire format the leaderboard accepts. A field whitelist runs before signing, so prompts, chain-of-thought, planner state, and tool-call internals never leave your environment — only the verifier-relevant fields do. - Email asm-bench@rapdev.io describing what you'd like to evaluate. We'll come back with what's involved and the next available slot.
- We run your agent against the test split on the pinned runner image, return per-task pass/fail and rubric scores, and (with your sign-off) post the row to the leaderboard.
Access is by request rather than self-serve because the test split's value depends on it staying out of training data. We don't need to know anything proprietary about your agent to score it — just an endpoint we can call.
What We Hope Happens Next
The honest version of why this benchmark exists: nobody currently knows, in a way that survives scrutiny, how good agents are at managing enterprise SaaS platforms. Vendors don't know. Buyers don't know. Researchers don't know. The conversations we have all the time — "is this agent ready for production?" "should we hand the CMDB cleanup over to it?" "can we trust it inside change control?" — get answered today with anecdotes and demos.
We'd like those conversations to be answered with evidence instead. asm-bench is a contribution toward that, not the last word on it. The corpus will grow, more platforms will land, and the methodology will tighten as the field pushes on it. The point isn't to crown a winner. The point is that the next time someone asks the question, there's a real place to look.
If you want to contribute a task, a platform, or a methodology improvement, reach out to us. And if you run an agent against the dev split, we'd genuinely like to hear what you find — including the parts that make us look wrong.
Healthy benchmarks make for healthy progress. Let's go find out what these agents can actually do. Reach out to us today to learn more.